Final Model
Steps required in any machine learning project are as
follow:
- Import the Data
- Clean the Data
- Split the Data into Training/ Test Sets
- Build the Model
- Train the Model
- Make Predictions
- Evaluate and Improve
The random dataset for the project
is created by myself which include three columns age,
gender and genre. In this dataset the genre preferred by the different age
group and gender is given.
First, we imported the pandas
module and loaded the csv file in the jupyter notebook.

After loading the data, we need to
prepare or clean the data by removing the duplicate data, null values etc. As
this dataset is already cleaned, we don’t need to further clean this dataset.
We need to split the dataset into
input set and output set. The age and gender are used as input set and the
genre is used as output set for creating a model. The output set is used for
the prediction.

After preparing the dataset we
need to create a model using an algorithm. Every algorithm has its pros and
cons in terms of performance and accuracy. For this project we will be using
decision tree algorithm. We don’t need to explicitly program these algorithm as
it is already implemented in the library called Scikit learn. The package
‘sklearn’ is used which is included in Scikit library in python. We will be
using ‘DecisionTreeClassifier’ class from ‘tree’ module which includes decision
tree algorithm. The object ‘model’ is created using instance of the class. And
we train this model and make prediction as shown below:


Measuring the accuracy of a model:
First, we need to split the
dataset one for training and another for testing as the entire data is used for
training. The general rule of thumb is to allocate 70% of the data for training
and other 30% for testing. Instead of passing only two sample for making
prediction we can pass dataset we have for testing. After that we can get
prediction and we compare the prediction with actual value in the test set
based on this we can calculate the accuracy. For this we need to import
‘train_test_split’ from the model ‘sklearn.model_selection’. With this function
we can split the dataset into training and testing datasets. Here, we allocate
20% of the data for testing. ‘X_train’ and ‘X_test’ variables are input sets
for training and testing and ‘y_train’ and ‘y_test’ are output sets. For
training the model instead of passing entire dataset we only pass training
dataset. And for making prediction instead of passing two sample we pass
‘X_test’ which contain input value for testing. For calculating the accuracy,
we need to compare the prediction with the actual value in output set for
testing by using the function ‘accuracy_score’. The more data we give to the
model and cleaner the data the better result is obtained. And we need more data
to build a complex model.


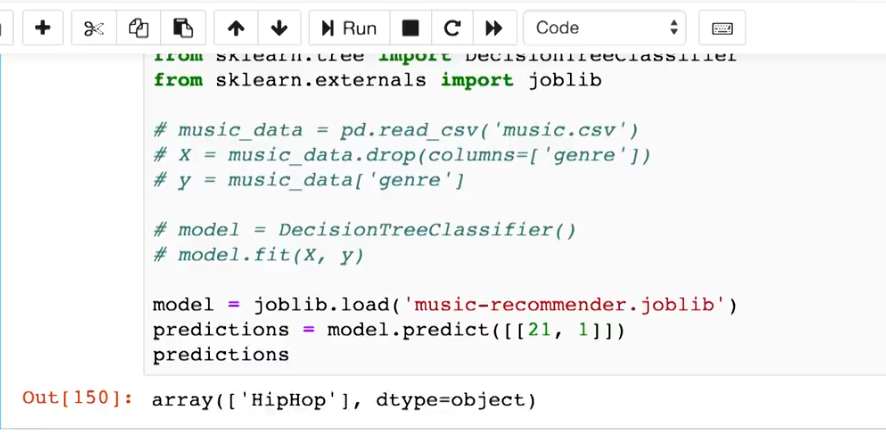
Model persistent
We build and train the model and save it to a file. So, next
time if we want to make prediction, we simply load the model from the file and
ask it to make prediction which is already trained. First, the function called
‘Joblib’ needs to be imported from the ‘sklearn.externals’ module. Joblib
object has methods for saving and loading models. After training the model we
store the trained model in a file as below:

After this we don’t need to train the model every time so
the part for loading the dataset and training are commented. Now, instead of
dumping the model we call the load method and simply pass the name of the model
file. And this returns the trained model and make prediction as shown below:
Visualizing a Decision Tree
We can also export
the model in visual format so that we can see how this model make a prediction.
To do this we need to import ‘tree’ function from ‘sklearn’ module. After
training the model with the help of ‘tree.export_graphviz()’ method we get a
.dot file which is graph description language. It is a textual language for
describing the graphs.

Lastly, we need to import this .dot file into vscode to
visualize a decision. For this we need to install Graphwiz dot extension in
vscode and the tree is shown as below:

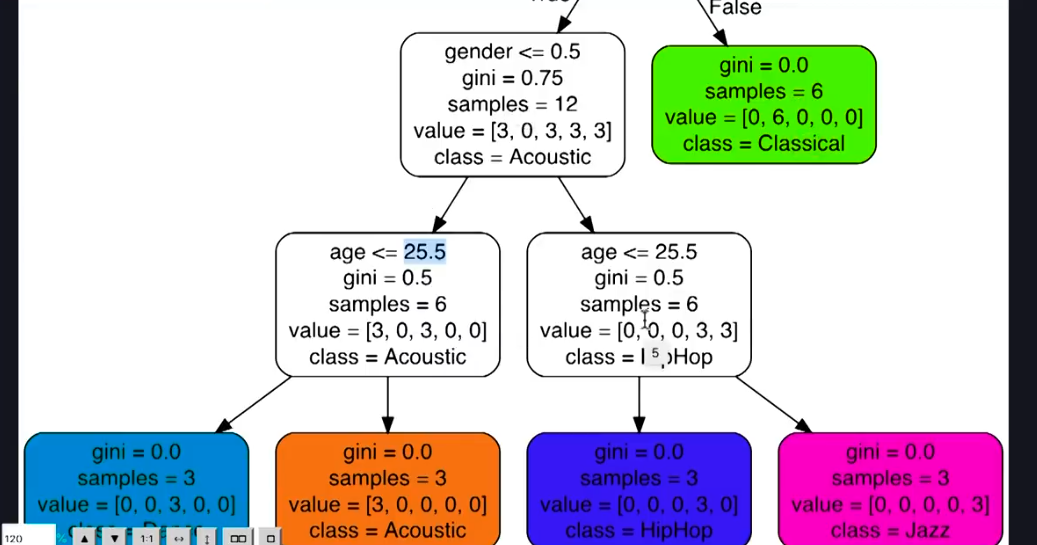
In this figure it is show how the model make a prediction.
It contains a binary tree which means every node can have maximum of two
children. On top of each node it has condition if it is true it goes down to
left side and if its false it goes down to right node. Here, we are classifying
people based on their profile. So, the person age of 30 or more belongs to
class of classical. If the condition for first node is true that means the
person is younger than 30 after that the gender condition is checked. If the
gender is less than 0.5 or female. After that in its child node there is two
conditions and we are dealing with female which is younger that 30. The age is
checked again if it is less than 25.5 if that’s the case then that user like
Dance music otherwise, they like Acoustic music. So, this is the decision tree
the model used to make prediction. The more column and feature the decision
tree gets more complex.
Comments
Post a Comment